
Product embedding with fasttext, have you tried ?
Word Embedding has been around for quite a while. Let’s apply these techniques for products.
Originally, Word2vec (or GloVe) vector embedding works with words in a sentence. The idea is simple: words that appear in the same context should have the same meaning, and vice versa. So we set up a model predicting whether or not a word appears in some neighborhood (a Bag Of Words, BOW). This idea is extended to other word embedding models, and proved successful in discovering linear structure within the corpus.

Word Embedding For Products: Word2vec
Let’s discuss how we can apply this in the context of E-commerce products.
In E-commerce, we have orders, which consists of a list of products, or Bag-Of-Products. We can set up a model predicting one item is in this Bag-of-item, and as a result, we can get a quite nice product embedding model.
Theoretically, bag-of-item for this task is very well suited than BOW for modelling a sentence, as a sentence is well beyond BOW modelling capability. Where an order can be thought as a sum of its products within.

Word Embedding For Products: Fasttext
However, Word2vec only gets you so far. It’s been pointed out that we have a hard time modeling rare words with Word2vec. The same with modelling rarely bought items in our problem. That’s where Fasttext comes in.
Fasttext assumes that the words morphics with the same root. This works particularly well in English or similar languages. For example: “Suggestion” and “Suggesting” are derived from the verb “Suggest”. Thus, by leveraging the sub-word information, we can train better word embedding, especially for rare words. We can even construct a good baseline embedding vector for new words, by combining its sub-word components. This is quite nice if you do embedding in noisy datasets (e.g: Online tweets), or in expansive languages.
This idea also applied well in training embedding for products. By representing a product with a list of it’s attributes, we can train a much better embedding model.
Example: Product_12123 ~ T-shirt + Blue Color + brand Nike + Dry Fit + ...
Now, the product attributes act as ‘sub-word’ information and help training more precise embedding.
Training the model
In Gensim, one of the most popular word2vec / fasttext training lib, and which I know and love, currently there is no way for us to specifically set up the sub-product information with precision. Doing this requires writing a custom Cython function, but luckily, it’s not that complex.
Some anecdotes
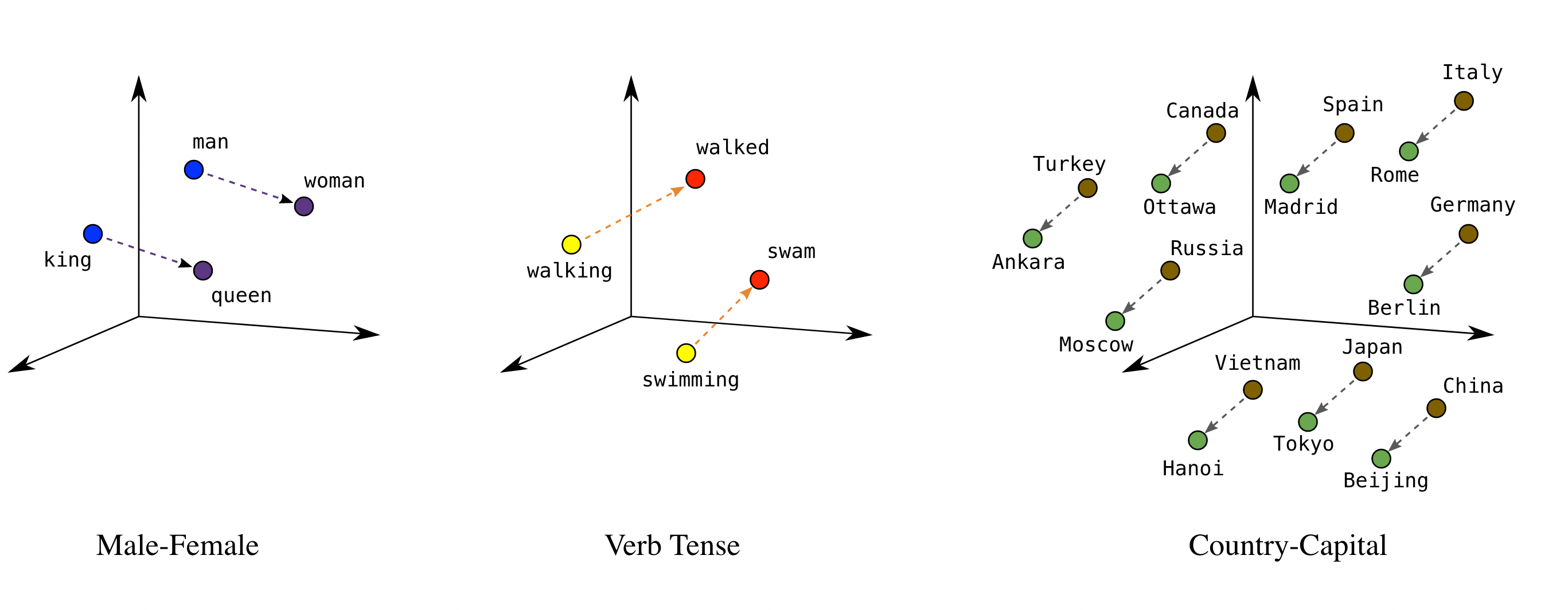
Let’s look into the most famous example of word2vec: Vector(king) - Vector(man) + Vector(woman) = Vector(Queen). This suggests that there is a vector ( with a magnitude and direction) representing the King-ly-ness in the embedding space. In the embedding space of products, we can find such vectors for different relationships between products: Cheapness, Blue-ness…etc. This is very helpful for setting up recommendation engines, such as finding the cheap replacement for a product for example.
Update: Example notebook, using a public dataset from kaggke